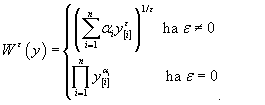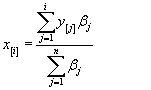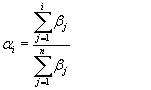|
|
|
A probléma az, hogyan tudunk olyan mutatószámot választani, hogy egyrészt teljesítse az alább kifejtendő axiómákat, másrészt alkalmazható legyen akkor is, amikor az elemzéshez az egyéni adatok nem állnak rendelkezésre, hanem csak csoportokba összevonva.
Az egyenlőtlenség mérésének leggyakoribb útja megfelelően választott mutató számszerűsítését jelenti. Az első módszertani kérdés így a megfelelő statisztika kiválasztása. Az irodalomban számtalan mutató áll rendelkezésre, amelynek értékkészlete s a mögöttes koncepció különbözősége folytán egészen más értékek adódnak az egyenlőtlenség mértékére. Tovább nehezítheti a választást, hogy számos mutató esetében valójában mutatócsaládról kellene beszélnünk, s a számszerűsítést néhány paraméter meghatározásának kell megelőznie. Ezáltal maga az egyenlőtlenség mértéke nem nevezhető az eloszlások „robusztus” jellemzőjének: erősen függ a zsinórmérték megválasztásától. Kevésbé változékony eredményeket kapunk akkor, ha komparatív statikai vizsgálatot végezve, a változás irányára vagyunk kíváncsiak. Jelen esetben a vizsgálatba bevont összes mutató azonosan rendezte az eloszlásokat egyenlőtlenségi szempontból, amely eredmény igen plauzibilisnek tűnhet az 1. és a 2 . ábra alapján. Az ábrák rámutatnak, hogy a vizsgálat tárgyául választott két év között jelentős eltérés mutatkozik, amelynek nagyságrendje meghaladja az egyes mutatók közötti különbségek nagyságrendjét. Mindazonáltal ezen eredmények nem helyettesíthetik a mutató választásának komoly megfontolását, amely a diszciplína fejlődési irányát figyelembe véve, leginkább az axiomatikus megközelítés alkalmazását jelenti.
Az egyenlőtlenség axiomatikus mérése során az egyenlőtlenségi mértéket néhány, az egyenlőtlenség lényegét megragadó axióma segítségével vezetjük le. A szokásos megközelítés társadalmi jóléti függvényt definiál a társadalom egyedeinek jövedelmi vektora felett előre meghatározott axiómák segítségével. Második lépésben a társadalmi jóléti függvényt felhasználva tudunk egyenlőtlenségi mutatókat konstruálni. Bár ez utóbbi lépésre többféle megoldás is létezik, s közel nem egységes az alkalmazás, mégis a főbb figyelem az első lépésre koncentrálódik: mi lesz az axiómák azon köre, amelyeket egy társadalmi jóléti függvénynek tudnia kell ahhoz, hogy az egyenlőtlenséget is kifejezően legyen képes a jövedelmi eloszlások rendezésére? A kérdés fontossága arra vezethető vissza, hogy az egyenlőtlenség mérése során a probléma magja valójában valószínűségi eloszlások rendezésének a meghatározása.
Minden egyes mutató, a társadalmi jóléti függvény éppúgy, mint az egyes egyenlőtlenségi mutatók – a relatív szórás, a Gini-együttható stb. – a jövedelemeloszlások bizonyos tulajdonságait egyetlen valós számban foglalják össze. Így kihasználva a valós számok teste felett természetes módon adódó kisebb-nagyobb relációt, implicit módon lehetővé teszi a jövedelemeloszlások teljes (nem irreflexív) rendezését. Ezért a továbbiakban is elsősorban eloszlások rendezéséről fogunk beszélni, amelyet analóg problémának tartunk az egyenlőtlenségi rendezéssel.
A rendezés alapjául szolgáló axiómák meglepő azonosságot mutatnak fel a különböző társtudomány-területeken, ahol az egyenlőtlenség mérése felmerül. A gondolat két fő axiómában összefoglalható, melyeket megelőz egy „nulladik” axióma. Ez egyszerűen azt a követelményünket fogalmazza meg, miszerint az eloszlásokon definiált rendezés teljes, reflexív, tranzitív, folytonos, s így reprezentálható társadalmi jóléti függvénnyel. Ez a feltevés biztosítja, hogy a vizsgálat tárgyát jelentő probléma létezik. A további két fő axióma az alábbi (mivel nem célunk, hogy részletesen tárgyaljuk az egyenlőtlenségi rendezések axiomatikus rendszerét, ezért a formális tárgyalást mellőzzük, s ebből adódhat néha kevésbé pontos fogalmazás).
1. Monotonitási axióma • Ha két rendezett jövedelmi vektor közül az egyik minden eleme nagyobb a másik megfelelő eleménél, akkor az előbbi preferált a másikkal szemben. Ez az axióma azt fejezi ki, hogy magasabb jövedelmi szint kívánatosabb. Az eloszlásfüggvények terminológiájában ezt úgy lehetne megfogalmazni, hogy a preferált eloszlás eloszlásfüggvénye az értelmezési tartomány minden pontja felett alacsonyabb értéket vesz fel („alatta halad”) a nem preferált eloszlásfüggvényhez képest.
2. Progresszív transzferek axiómája • Ha egy rendezett jövedelmi vektorból úgy képezünk egy új jövedelmi vektort, hogy egy adott összeget átcsoportosítunk egy magasabb jövedelmű személytől egy alacsonyabb felé anélkül, hogy ezzel megváltoztatnánk a jövedelmek sorrendjét, akkor ez utóbbi jövedelmi vektor preferált az előbbivel szemben. Az eloszlásfüggvények terminológiájában ez azt jelenti, hogy az előbbi eloszlás eloszlásfüggvénye alatti terület az értelmezési tartomány minden pontjára kisebb, mint az átrendezés után adódó. A koncepció azt kívánja megragadni, hogy azonos átlagjövedelmű vektorok esetén azt preferáljuk, amelyiknél az egyes jövedelmek átlagtól való távolságai „kevésbé rendezetlenek”.
A társadalmi jóléti függvények definiálásához e két axióma „szállítja” az egyenlőtlenségi koncepciót. Ezt még gyakorta kiegészítik a relatív versus abszolút egyenlőtlenség koncepciójával. Egy társadalmi jóléti függvény akkor elégíti ki a relatív invariancia tulajdonságát, ha első fokon homogén függvénye az egyes jövedelmi értékeknek. Ebben az esetben, ha minden jövedelem értéke ugyanolyan arányban változik, a társadalmi jóléti függvény értéke is arányosan változik, s így a megfelelően definiált egyenlőtlenségi mutató értéke változatlan marad.
Ebert (1986) tanulmánya alapján a lényegében a fenti axiómáknak eleget tevő társadalmi jóléti függvényt a következők szerint lehet felírni:
|
|
(6) |
ahol y [ i ] a jövedelmi értékek csökkenően rendezett vektora, azaz y [ i ] ≥ y [ i +1], az αi súlyok összege 1. A progresszív transzferre vonatkozó axióma teljesüléséhez az is kell, hogy az ε úgynevezett egyenlőtlenségelutasítási paraméter értéke határozottan kisebb legyen, mint 1, és az αi súlyok monoton növekedő sorozatot alkossanak, azaz αi ≤ αi+1 teljesüljön (vagy ε = 1 és αi < αi+1 ). Ez utóbbi feltétel valójában azt fogalmazza meg, hogy minél magasabb egy vizsgált jövedelmi kategória, annak mutatóban szereplő súlya annál kisebb legyen.
Az (6) alatt meghatározott társadalmi jóléti függvény kellően tág függvényosztályt jelent az α és az ε paraméterek megválasztásával ahhoz, hogy számos ismert egyenlőtlenségi mutatót levezethessünk belőle, például az Atkinson- és az általánosított Gini-együtthatót. A mutatók számításához a paramétereket úgy kell megválasztani, hogy teljesüljenek a fenti axiómák. Egyedi adatok esetében ez könnyen lehetséges, például ε = 1 és αi = 1 /n választással. Csoportosított adatok esetében, mint az egyenlőtlenségek jellemzéséről szóló fejezetben említettük, a csoportba tartozó megfigyelések száma természetesen jelöli ki a súlyok értékét, ezekre azonban a jövedelmek közel lognormális eloszlása és az azonos hosszúságú intervallumból adódóan nem fog teljesülni az αi ≤ αi+1 követelmény. Ez azt jelenti, hogy az adatokra alkalmazott fenti kifejezés nem fogja teljesíteni a progresszív transzferek axiómáját, amelyet az egyenlőtlenségi koncepció talán legfontosabb kitételének nevezhetünk, ha van értelme ilyen megkülönböztetésnek.
Elkerülhetjük ezt a problémát akkor, ha elvetjük a népességszám adta természetes súlyértékeket, és egyéb megfontolások alapján rendelünk súlyokat az egyes csoportokhoz. Álláspontunk szerint csoportosított adatok esetében ez nem feltétlen jelenti a legszerencsésebb megoldást. A csoportnagyság fontos információt hordoz, amelyet az alapadatok ismeretének hiányában célszerű beépíteni az elemzésbe. Ezért eljárhatunk a következők szerint is – megőrizve a népességszám nyújtotta információt és teljesítve az axiómák követelményeit is. Jelölje továbbra is a csökkenő sorrendbe rendezett csoportátlagokat y [ i ], s a hozzá tartozó súlyokat (népességszámokat) βi . Az egyenlőtlenség számítását a csoportátlagok helyett a kumulált átlagokra végezzük el: ebben az esetben az egyes jövedelmi szinthez tartozó súly, amely az adott átlagos jövedelemhez tartozó népességnek a teljes populációhoz való arányát fejezi ki, teljesíteni fogja a progresszívtranszfer-axióma teljesüléséhez szükséges feltételeket. A kumulált átlagokat x [ i ]-vel jelölve, a (7) kifejezéssel számíthatjuk az alapadatok ( y [ i ] és a korábbi súlyok, βi ) segítségével:
|
|
(7) |
A kumulált átlaghoz tartozó αi súlyokat pedig a következők szerint határozhatjuk meg:
|
|
(8) |
Mivel az eredeti y [ i ] adatok a csoportátlagok csökkenő sorrendbe rendezett vektorát jelölték, ezért a kumulált átlagok x [ i ] vektora szintén monoton csökkenő lesz, azonban elemei y [1] és y* között vesznek fel értékeket. A súlyok αi vektora pedig monoton növekedő lesz, hiszen az egyes βi értékek mind pozitívak.
Az alapadatokból a (7)–(8) egyenletek által definiált kumulált átlagok és a hozzájuk tartozó gyakorisági vektorok olyan adatsort alkotnak, amelyek teljesítik az egyenlőtlenségi rendezésben a súlyokkal szemben támasztott követelményeket és a belőlük számított egyenlőtlenségi mutatók teljesítik a fenti axiómákat. Óvatosnak kell lennünk azonban a kapott eredmények értelmezésével. A kumulált átlag alapján számított egyenlőtlenség alulbecsüli a tényleges jövedelmi különbségeket azáltal, hogy kisimítja az adatokat, és jelentősen csökkenti az egyes értékek közötti különbségeket. Ezért az általunk ismertetett eljárást leginkább arra tartjuk alkalmasnak, hogy komparatív statikai vizsgálatokat végezve, a egyenlőtlenség változásának irányára rámutasson. E tekintetben az eredmények alátámasztják az általunk korábban írottakat. A kumulált átlagok alapján számított mutatók egyaránt az egyenlőtlenség csökkenésének irányába mutatnak. Mivel e számítás a jóléti rendezés axiómáit teljesítő mutatók számszerűsítésével történt, úgy gondoljuk, hogy megerősítik korábbi eredményeinket.